This post covers the main findings from my undergraduate dissertation. I built and evaluated AutopsyMCP, a natural language interface for the Autopsy digital forensics platform built on Anthropic’s Model Context Protocol. I’ll cover what it does, what worked, what failed, and what the results mean for anyone thinking about AI in forensic or security workflows.
The Problem
Digital forensic investigations are cognitively expensive. Not just technically hard — cognitively hard, in a specific way that the tooling does little to alleviate.
Here’s a realistic example. An investigator suspects a user downloaded confidential files after visiting a file-sharing site. To answer “which files were downloaded within 30 minutes of visiting fileshare.example.com”, they have to:
- Open the Web Artifacts section, find the relevant browser history entries
- Note the timestamps of visits to the suspicious domain
- Switch to Recent Documents or navigate the Directory Tree for recently created files
- Manually compare timestamps across both views
- Cross-reference in the Timeline module to confirm event ordering
Five context switches to answer one question. Each switch is an opportunity to lose track of a finding, and the only record of the process is whatever notes you remembered to take.
Autopsy is an excellent platform. It parses disk images, recovers deleted files, examines file system artifacts, parses browser history, email, messaging data, and much more. But like most forensic tools it’s GUI-centric: you navigate to evidence rather than querying for it. The desire for a more assistant-like interface isn’t new. Hibshi et al. documented it as far back as 2011, and Reddy and Faklaris argued in 2024 that the usability problem still warrants serious attention.
There’s also a scale problem. Police forces and forensic labs report hundreds to thousands of devices awaiting analysis. Casey et al. described traditional comprehensive examination as “rapidly untenable” in 2009. It hasn’t improved.
The question this project asks is: can a natural language interface built on the Model Context Protocol make this meaningfully better — and can it do so without compromising the evidence integrity standards forensic work legally requires?
What is MCP?
The Model Context Protocol (MCP) is an open standard introduced by Anthropic in November 2024. If you haven’t come across it: MCP lets LLMs connect to external tools and data sources through a standardized, composable interface, rather than through one-off bespoke integrations. Think of it as a universal adapter, write a server once and any MCP-compatible client (Claude Desktop, Cline, etc.) can use it.
An MCP setup has two sides:
- Server: exposes tools (callable functions), resources (data), and prompts (pre-authored instruction templates) via a well-defined JSON-RPC interface
- Client: an AI assistant that discovers available tools at runtime and invokes them to fulfill requests
Most relevant for forensics: every tool invocation is explicit and can be logged. The model doesn’t just “know” something; it makes a discrete, auditable call to retrieve it.
Hilgert et al. (2025) published the first academic analysis arguing MCP is well-suited to forensic applications because of this architecture. They explicitly called for practical integration with real forensic tools as future work. This project takes that up directly.
The Architecture
AutopsyMCP consists of two main components: a Java plugin embedded in Autopsy exposes case data through a REST API on localhost:8080, and a Python MCP bridge wraps that API as callable tools and presents them to Claude Desktop.

AutopsyMCP system architecture
Java Autopsy Plugin
A NetBeans ModuleInstall subclass that starts an HTTP server on localhost:8080 when Autopsy loads, binding 22 read-only REST endpoints to Autopsy’s internal SleuthkitCase API.
@Override
public void restored() {
startHttpServer(); // binds port 8080, registers all handlers
}
Most handlers follow the same broad pattern: parse query parameters, read data through Autopsy’s case APIs, serialize results to JSON, and return. File metadata, for instance:
AbstractFile file = skCase.getAbstractFileById(fileId);
json.put("md5", file.getMd5Hash());
json.put("sha256", file.getSha256Hash());
json.put("mtime", file.getMtime());
json.put("path", file.getUniquePath());
The plugin exposes whatever Autopsy has already computed and doesn’t trigger ingest itself. If the relevant ingest modules haven’t been run on the case, the corresponding data won’t be available to query.
The plugin installs as a standard .nbm file through Autopsy’s existing plugin manager.

Screenshot of Autopsy Plugins panel showing AutopsyMCP installed and active
Python MCP Bridge
A single Python file (bridge_mcp_autopsy.py) implementing a FastMCP server. At the time of writing, it exposes 23 tools and 6 prompt playbooks. These are distinct MCP primitives and each plays a different role in an investigation.
All tool calls route through a safe_get() utility that handles connection errors, timeouts, and non-200 responses:
def safe_get(endpoint: str, params: dict = None) -> dict: # simplified for brevity
url = urljoin(autopsy_server_url, endpoint)
try:
response = requests.get(url, params=params, timeout=15)
return response.json() if response.ok else {"error": f"HTTP {response.status_code}"}
except requests.exceptions.ConnectionError:
return {"error": "Cannot connect to Autopsy server."}
The bridge runs with stdio transport: Claude Desktop spawns it as a child process and exchanges MCP JSON-RPC over stdin/stdout.
Put together, a single question in Claude Desktop flows through the stack like this:

Request flow through the AutopsyMCP stack, from natural language input to tool result.
Tools vs. Prompts
Tools: invoked at runtime to retrieve data
A tool is a function the model can call during a conversation to get information. Each tool is decorated with @mcp.tool(), has typed parameters, and its docstring becomes the description the model uses to decide when to invoke it:
@mcp.tool()
@audit_tool
def get_file_metadata(file_id: int) -> dict:
"""
Get detailed metadata for a specific file.
Args:
file_id: File row id.
Returns:
Path, size, extension, MIME, MD5/SHA256, MAC times,
data source, and related fields.
"""
return safe_get("case/file/metadata", {"id": file_id})
When an investigator asks “what’s the SHA256 of file 4821?”, the model reads the available tool descriptions, infers get_file_metadata is the right call, invokes it with file_id=4821, and uses the returned JSON to formulate an answer. The investigator never writes a query or navigates a UI.
The full tool set covers five categories:
| Category | Tools |
|---|---|
| Case orientation | health_check, get_case_overview, get_data_sources, get_volumes, get_os_accounts |
| File navigation | search_files_by_name, get_file_metadata, list_directory, find_directories, count_directory_contents |
| File content | get_indexed_text, get_file_hex, get_file_strings, extract_file_to_disk, get_extracted_files |
| Artifacts & tags | list_artifacts, get_file_artifacts, get_artifact_types, get_tags |
| Timeline & search | get_timeline_minmax, get_timeline_event_types, get_timeline_events, keyword_search |
Prompts: pre-authored instruction templates injected when selected
A prompt is registered with @mcp.prompt() rather than @mcp.tool(). It’s not something the model calls at runtime: it’s a pre-authored instruction string that appears in Claude Desktop’s prompt library and is injected into context before the model begins reasoning when an investigator selects it.
@mcp.prompt()
def reconstruct_user_activity() -> str:
"""Web history, searches, program execution, and recently accessed files."""
return (
"list_artifacts() for TSK_WEB_HISTORY, TSK_WEB_SEARCH_QUERY, TSK_WEB_DOWNLOAD, "
"TSK_WEB_COOKIE, TSK_WEB_BOOKMARK, TSK_PROG_RUN, and TSK_RECENT_OBJECT. "
"For anything interesting call get_file_metadata() for hashes. "
"Build a chronological narrative. Flag sensitive files, unusual executables, "
"paste sites, or file-sharing services."
)
This is Hilgert et al.’s prompt specificity level in practice: explicitly prescribing a tool sequence rather than leaving sequencing entirely to the model’s discretion.
Why not just hardcode the workflow? Hardcoded sequences would guarantee consistent execution but at the cost of adaptive reasoning. An investigator working an unfamiliar case needs the model to follow leads as they emerge, not execute a predetermined script. Prompt-level orchestration is a middle ground: the playbook provides investigative structure and a preferred tool sequence, the model retains the flexibility to adapt when evidence demands it.
The six playbooks are organized by investigative goal rather than by tool:

Investigation prompt playbooks diagram
These six cover the core investigative spine and are enough to demonstrate the pattern, but the library is deliberately extensible: additional playbooks targeting more specific workflows can be added without touching the underlying tool set. Their performance against investigator-written prompts hasn’t been tested, though it’s a natural direction for future work.
The clip below shows the reconstruct_user_activity prompt being invoked from Claude Desktop and executed against an open case. Watch how the model sequences tool calls autonomously without the investigator specifying any of them. The playbook prescribes the investigative goal; the model handles the retrieval chain.
Playbook selection demonstration
Malware hunting demonstration using the find_malware_on_system playbook (skip to ~3:07 to view the output report)
The generate_ioc_list playbook targets the reporting phase rather than active investigation. Here’s an example output on the Beethomahler image:

Sample output from the generate_ioc_list playbook (part 1 of 2)

Sample output from the generate_ioc_list playbook (part 2 of 2)
One idea I’m considering is adding optional parameters to prompts. For example, letting the investigator specify an output format directly when invoking generate_ioc_list rather than describing it in the query.

generate_ioc_list playbook with an optional format parameter
In practice this isn’t a significant gap since you can just specify your preferred format in the prompt itself and the model will follow it. But surfacing it as a named parameter is more intuitive and makes the capability more discoverable.
Audit Logging
Audit logging is what determines whether AutopsyMCP is useful in a legal context, not just a research one.
Every tool call is intercepted by an @audit_tool decorator before the result is returned to the model:
def audit_tool(fn):
@wraps(fn)
def wrapper(*args, **kwargs):
t0 = time.time()
result = fn(*args, **kwargs)
duration_ms = round((time.time() - t0) * 1000)
_write_audit({
"event": "tool_call",
"tool": fn.__name__,
"case_name": _get_current_case_name(),
"args": kwargs,
"duration_ms": duration_ms,
**_summarize_response(result if isinstance(result, dict) else {}),
})
return result
return wrapper
Here’s what a representative investigative session looks like in the audit log:
{"event": "session_start",
"autopsy_server": "http://127.0.0.1:8080/",
"timestamp": "2026-03-12T14:02:11.004Z",
"session_id": "a3f9..."}
{"event": "http_call",
"endpoint": "case/files/by-name",
"params": {"query": ".evtx", "limit": 50, "offset": 0},
"duration_ms": 41,
"timestamp": "2026-03-12T14:02:14.231Z",
"session_id": "a3f9..."}
{"event": "tool_call",
"tool": "search_files_by_name",
"case_name": "Beethomahler",
"args": {"query": ".evtx", "limit": 50},
"duration_ms": 43,
"count": 7,
"timestamp": "2026-03-12T14:02:14.229Z",
"session_id": "a3f9..."}
{"event": "file_extracted_for_delegation",
"file_id": 12847,
"file_name": "Security.evtx",
"file_size": 69632,
"extracted_path": "C:\\Users\\...\\autopsymcp-output\\
Beethomahler_12847_Security.evtx",
"timestamp": "2026-03-12T14:02:19.880Z",
"session_id": "a3f9..."}
Each record carries a UTC timestamp and session UUID, so all events from a session can be correlated. Four event types appear across a session:
session_start: establishes the investigative session with a unique IDhttp_call: records the raw REST request to Autopsy, independently of the tool layertool_call: records the MCP tool invocation as the model called it — name, arguments, response summary, durationfile_extracted_for_delegation: marks the exact point a file leaves AutopsyMCP’s audit custody for a specialist server. What the specialist server does with it is outside the bridge’s audit scope, but the handoff itself is on record.
This addresses the core chain-of-custody requirements to the extent an LLM-assisted workflow can: who accessed the evidence, when, what actions were performed, and under what authority.
Two acknowledged limitations: the log doesn’t implement cryptographic integrity protection (tamper-evident logging is noted as future work), and it captures actions but not reasoning — the model’s inferential steps live in the conversation transcript rather than the audit record. This tension is the subject of the forensic soundness section below.
Specialist Servers and the Delegation Architecture
To evaluate what delegation actually adds, the entire project was run in three modes: manual Autopsy (Mode 1), MCP without specialist servers (Mode 2), and MCP with the full specialist stack (Mode 3). Mode is determined by the combination of server declarations in the MCP config, per-tool permission controls in Claude Desktop, and server-level toggles for specialist servers. Understanding how that distinction works mechanically is what the rest of this section covers.
The Specialist Servers
For certain artifact types that benefit from dedicated parsing, Mode 3 adds four specialist MCP servers alongside the core bridge:
| Server | Purpose | Source |
|---|---|---|
| EventWhisper | Windows Event Log (.evtx) parsing |
Open-source, Git submodule |
| regipy | Offline registry hive analysis | Open-source, Git submodule |
| SQLite | Read-only querying of extracted database files | Built for this project |
| VirusTotal | Hash reputation lookup | Built for this project |
The Delegation Pivot: extract_file_to_disk
The primary mechanism connecting the core bridge to file-based specialist servers is extract_file_to_disk. It decodes the Base64 binary response from /case/file/binary, writes the file to %USERPROFILE%\autopsymcp-output under a caseName_fileId_fileName naming scheme, and returns the extracted local path.
That path is then available for specialist servers to consume. The tool’s docstring explicitly signals this: “the returned path may be passed to another MCP server that can read that path.”
Each specialist server’s tools describe the file types they accept. When the model encounters a .evtx in a file listing, the inference — extract it, then pass the path to EventWhisper — follows naturally from the combined tool descriptions. No dispatcher or routing rules are involved. The architecture is what Hilgert et al. call implicit inference constraint: server design guides model behavior through documentation rather than enforcement.

Delegation flow in Mode 3. The model routes to the appropriate specialist server based on the artifact type being handled, as inferred from tool descriptions. No explicit dispatcher is involved.
Defining the Three Modes
The MCP config for Claude Desktop is at %APPDATA%\Claude\claude_desktop_config.json. The full Mode 3 config looks like this:
{
"mcpServers": {
"autopsy": {
"command": "python",
"args": ["bridge_mcp_autopsy.py", "--autopsy-server", "http://127.0.0.1:8080/"]
},
"eventwhisper": {
"command": "poetry",
"args": ["-C", "mcp_servers\\EventWhisper", "run", "python", "-m", "eventwhisper.mcp.server"],
"env": { "PYTHONIOENCODING": "utf-8" }
},
"regipy": {
"command": "python",
"args": ["mcp_servers\\regipy\\regipy_mcp_server\\server.py",
"--hives-dir", "C:\\Users\\...\\autopsymcp-output"]
},
"sqlite": {
"command": "python",
"args": ["mcp_servers\\sqlite-mcp\\server.py"]
},
"virustotal": {
"command": "python",
"args": ["mcp_servers\\virustotal-mcp\\server.py"],
"env": { "VT_API_KEY": "<key>" }
}
}
}
Each server is spawned as a child process by Claude Desktop at startup. In Mode 3, Claude Desktop presents the combined tool namespace of all five servers simultaneously and the model sees all tools from all servers and selects among them.
Mode 2 uses the same config but with all delegation pathways closed: extract_file_to_disk and get_extracted_files disabled in Claude Desktop’s per-tool permission controls, and specialist servers toggled off at the server level. No delegation occurs even if the servers are declared in the config.
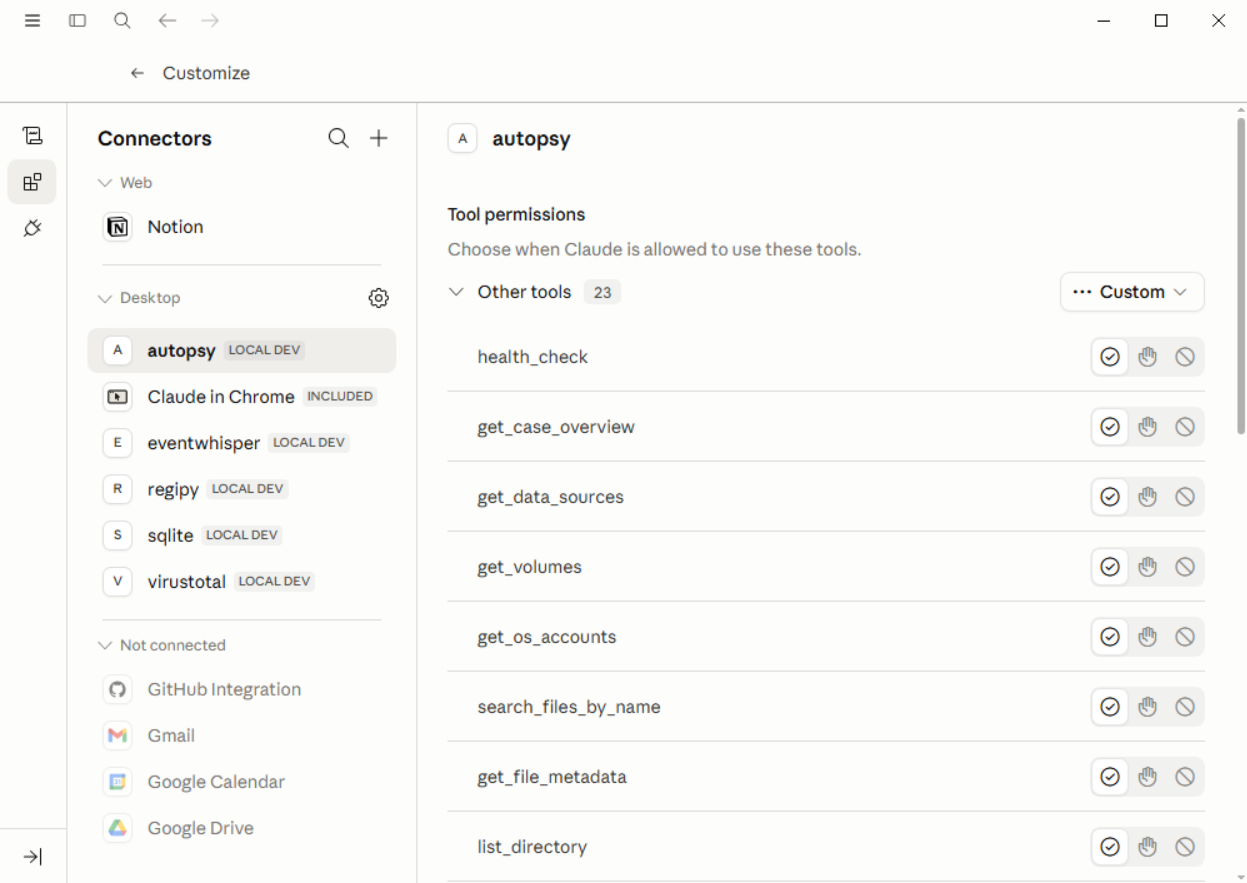
Claude Desktop Connectors panel showing all five MCP servers registered and the per-tool permission controls for the autopsy server. These per-tool controls govern the file-based extraction pathway; server-level toggles (shown in the next figure) govern the remaining specialist servers.
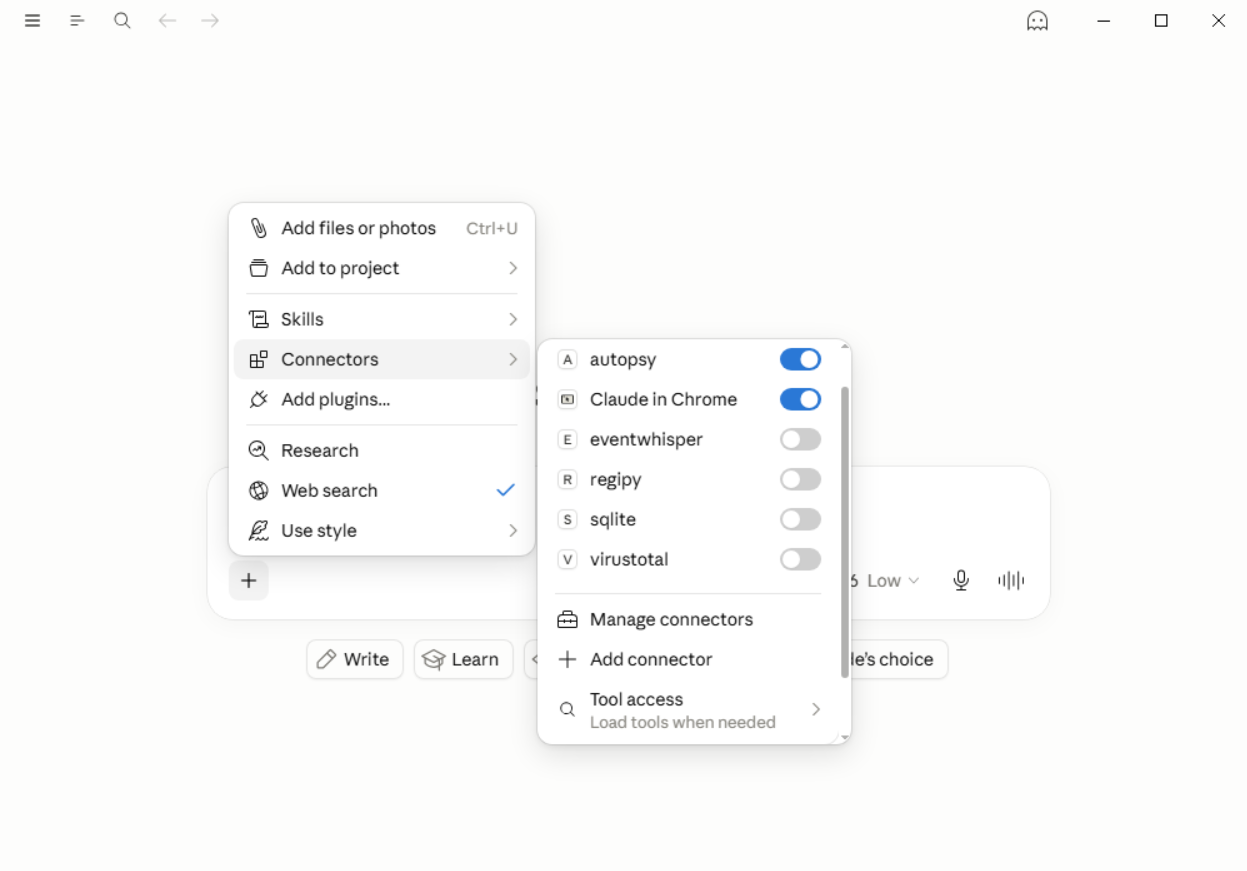
Server-level toggles in Claude Desktop control specialist servers independently of the per-tool extraction pathway. In Mode 2, these are toggled off alongside the extraction tools to close all delegation pathways.
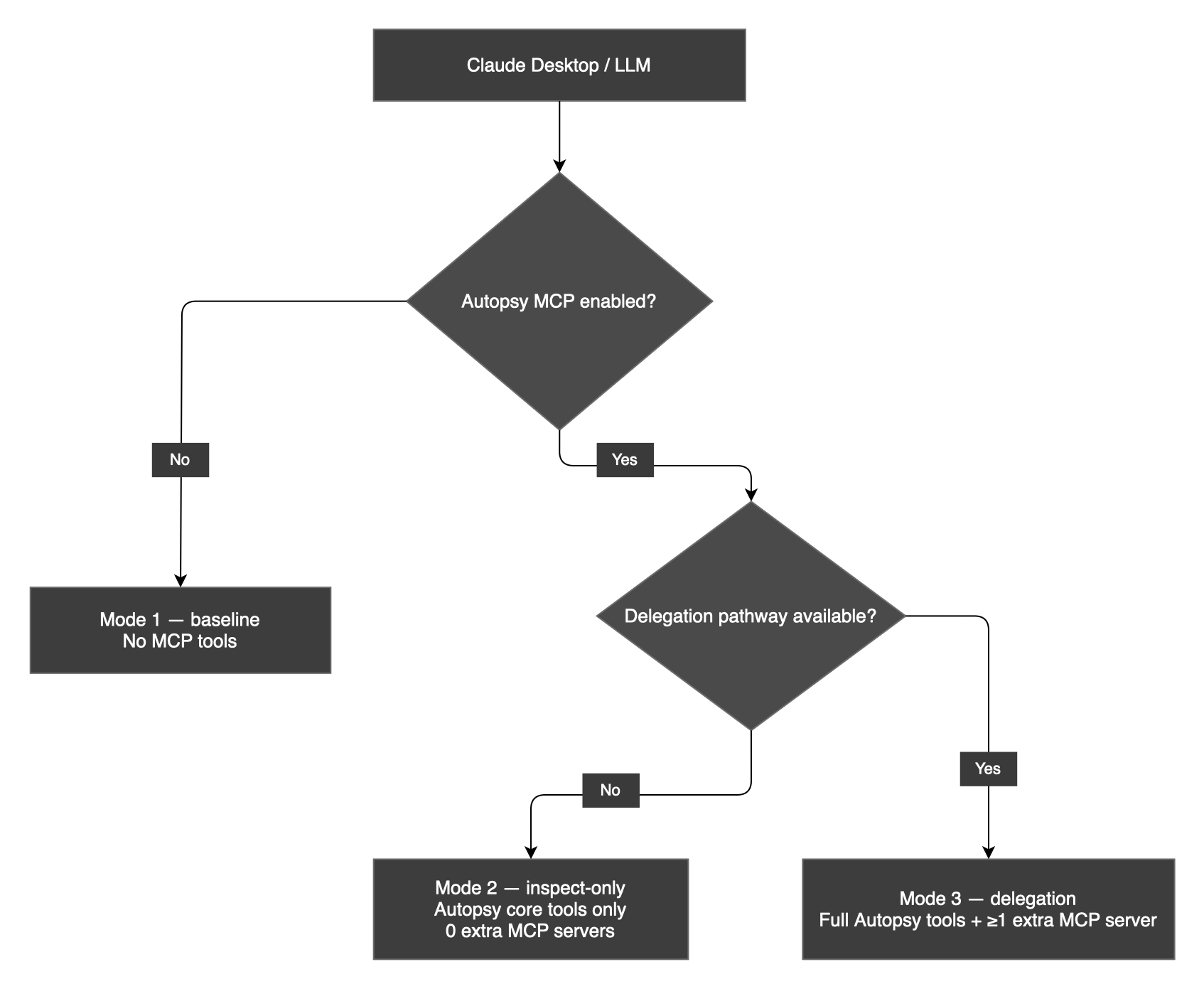
Mode is determined by the combination of Claude Desktop tool controls and server declarations in the MCP config file. In Mode 2, all delegation pathways are closed — extraction tools disabled and specialist servers toggled off.
This composability is intentional. Investigators who only need the Autopsy integration run Mode 2 with no additional setup. Mode 3 is opt-in per artifact domain, and additional servers covering other artifact types (Windows execution artifacts, for example) can be added without modifying the core bridge.
Evaluation Design
All evaluation used Claude Sonnet 4.6. Tasks were run by a single evaluator (me, also the developer) across three modes:
- Mode 1: Manual Autopsy, optionally supplemented by standard forensic tools (Eric Zimmerman’s suite, etc.)
- Mode 2: AutopsyMCP bridge + Claude Desktop, no specialist servers
- Mode 3: AutopsyMCP + all four specialist servers
Micro-benchmark: 10 targeted forensic questions across 5 different forensic images (GregSchardt, Stanley, Norman, IPTheft, Animal), each with a known ground-truth answer, spanning a range of artifact types.
Full case investigation: 20 questions on the Beethomahler forensic image in CTF format, all answers independently verifiable. Tasks run sequentially within a single investigative session per mode.
Metrics per task: time to completion, answer given, correctness (correct / partial / incorrect / not found), and investigator actions (manual steps for Mode 1, queries sent for Modes 2 and 3).
Prompting protocol: each task was presented as a single natural language question with no guidance on which tool or artifact type to use. No follow-up prompts were issued unless the system itself requested clarification, and tasks were terminated where the system was clearly not progressing toward a solution.
Results
Micro-Benchmark
| Metric | Mode 1: Manual | Mode 2: MCP Only | Mode 3: MCP + Delegation |
|---|---|---|---|
| Time Performance | |||
| Avg time per task | 93.7s | 118.5s | 70.6s |
| Median time per task | 50.3s | 61.3s | 60.0s |
| Slowest task | Task 1 · 415.4s | Task 3 · 536.3s | Task 9 · 219.0s |
| Fastest task | Task 6 · 8.3s | Task 6 · 9.7s | Task 6 · 16.6s |
| Accuracy | |||
| Correct | 10/10 | 7/10 | 7/10 |
| Partial | 0 | 1 | 3 |
| Incorrect / not found | 0 | 2 | 0 |
| Effort | |||
| Avg steps / queries per task | 3.3 steps | 1.0 queries | 1.0 queries |
10 tasks across 5 forensic images. Bold = best in each row.
Mode 1 achieved perfect accuracy. Mode 3 was fastest on average and produced no outright failures (though 3 partials). Mode 2 had the highest failure rate. Both MCP modes required only 1.0 queries per task on average — a significant reduction from 3.3 manual steps.
Task 1 (last shutdown time, GregSchardt image) illustrates the delegation benefit most clearly. Manual investigation required locating the SYSTEM hive, interpreting a hexadecimal little-endian timestamp, and downloading an external conversion tool (DCode). Total: 6 minutes 55 seconds, 4 steps.
Mode 3 extracted the hive, loaded it into regipy, and ran the shutdown plugin directly. Total: 64 seconds, 1 query.

Delegation chain: extract_file_to_disk → regipy → answer
The model chains the tool calls across the MCP servers (AutopsyMCP and regipy) without the investigator specifying any of the intermediate steps.
Task 2 (IP and MAC addresses) showed the opposite of Task 1: delegation failed where simpler retrieval succeeded. Mode 3 got the IP address via regipy’s network plugin almost immediately but couldn’t extract the MAC address, which is stored as a binary registry value requiring parsing that regipy couldn’t do as plain text. Mode 2 got both values from the system event log it had already retrieved during the previous query.
Task 3 (network cards) was Mode 2’s slowest task at nearly 9 minutes. It went down a chain of dead ends: NETLOG.txt, Ethereal preferences files, and Dell Latitude CPi-specific driver searches. Notably, it used its training knowledge about the specific laptop model to guide the investigation, which is both useful (it knew which adapters that model typically had) and a liability (it anchored on those expectations rather than what the evidence actually showed).
Task 5 (files larger than 50MB) produced the most instructive failure. Mode 2 searched systematically and concluded: “No files of 50MB or more were found in the image.” Two such files existed. Mode 3 solved it correctly by listing full directory contents and filtering programmatically. More on this failure pattern below.
Task 6 (sector length of vol3) revealed an interpretation gap. Mode 2 mapped the JSON response’s raw volume ID numbering to Autopsy’s UI partition numbering — which skips unallocated spaces — and returned an incorrect sector count. Mode 3 correctly identified the allocated partition. In manual mode, the answer was immediately visible as a column in Autopsy’s partition listing table. This failure illustrates a broader liability of the knowledge-equalizer effect. The model applied training knowledge about partition numbering rather than reasoning strictly from the data returned — and gave no signal that it was doing so. Kadavath et al. (2022) show that LLMs have latent calibration that correlates with correctness but doesn’t reliably surface in generated answers. Knowledge equalization and confident misapplication come from the same mechanism.
Task 8 (activity years) showed a subtler failure in Mode 3: it used limit=1 in its initial 2014 query just to check whether events existed, then presented those partial results as a complete year-by-year summary. Lazy querying producing plausible-looking but incomplete conclusions. Mode 2 made no such shortcut and got it right.
Full Case Investigation
| Metric | Mode 1: Manual | Mode 2: MCP Only | Mode 3: MCP + Delegation |
|---|---|---|---|
| Time | |||
| Total investigation time | 21.3 min | 19.2 min | 21.4 min |
| Accuracy | |||
| Correct (out of 20) | 19 | 16 | 15 |
| Partial | 0 | 0 | 1 |
| Incorrect / not found | 1 | 4 | 4 |
| Effort | |||
| Total steps / queries | 54 steps | 20 queries | 20 queries |
20 CTF-style questions on the Beethomahler image, run sequentially within a single session per mode.
The 63% reduction in investigator interactions (54 steps → 20 queries) held across the full investigation. Mode 2 was fastest overall. Mode 3 matched Mode 2 on accuracy but took slightly longer due to delegation overhead on tasks where the simpler path would have sufficed.
Context retention was one of the more significant findings. Seven of the twenty questions were answered from information already retrieved during earlier queries, with no additional tool calls needed. Tasks 11, 12, and 13 were all answered from the Chrome download artifact data surfaced during Task 10.

Later queries resolved from earlier conversation context
In manual investigation, previously found evidence has to be actively tracked and re-navigated to. Here it simply persists in context.
That said, accumulated context proved fragile in two ways. Session termination — which occurred twice during the full case — discarded everything, forcing full re-establishment of earlier evidence chains from scratch. And prior context doesn’t expire: Laban et al. (2025) characterize exactly this pattern — LLMs over-rely on early assumptions in subsequent turns, which is what caused Task 16’s GPS failure. Both MCP modes had encountered a geolocated image earlier in the session and anchored on it, rather than searching for additional GPS candidates. The manual investigator succeeded because Autopsy’s Geolocation module presented all GPS-tagged files simultaneously, with no prior session context to bias the view.
A qualitative advantage observed across both MCP modes was the richness of output beyond just the answer. Task 7 returned not just camera make and model but contextual device information about the Nikon D40. Task 9 (micro-benchmark) saw both modes produce categorized evidence summaries with Claude’s built-in visualization capability, presenting findings in a way that would take significant manual effort to collate manually.

Sample evidence summary visualization produced by Mode 3 for Task 9 (IPTheft image)
Task 20 (counting WeTransfer visits in Chrome History, excluding page refreshes) was the clearest delegation win. Mode 1: 8 minutes 38 seconds, involving file extraction, loading into an external SQLite viewer, incremental SQL query construction, and WebKit timestamp conversion. Mode 2: failed entirely (attempted to reconstruct the database from hex dumps, terminated). Mode 3: 1 minute 46 seconds.

SQLite delegation resolving a task Mode 2 failed entirely (part 1 of 2)

SQLite delegation resolving a task Mode 2 failed entirely (part 2 of 2)
The model decoded Chrome’s bitmask-encoded transition types, distinguished typed navigations from page refreshes from email link clicks, and arrived at a forensically defensible count — without the investigator knowing anything about Chrome’s internal schema.
Task 19 (WMP installation error code) was the clearest delegation failure. Mode 2 solved it in 18 seconds by directly searching for setup log files. Mode 3 took 4 minutes 45 seconds and returned the wrong answer, having pursued an extended investigation through EventWhisper and WER crash reports before settling on an error code from a different event entirely.

Speculative EventWhisper delegation producing incorrect answer
The system explored a plausible but wrong line of inquiry and never fell back to the simpler search that solved the task in 17 seconds in Mode 2.
Where It Failed
1. Confident false negatives
Task 5’s Mode 2 failure wasn’t a search that returned nothing. It was a well-reasoned, confidently stated incorrect conclusion. The model scanned root and subdirectory contents, found $BadClus system metadata entries (which are large), correctly identified those as non-user files, and then incorrectly concluded no user files exceeded 50MB. A partial hedge appears at the end of the response, but after a bold confident verdict it reads as an afterthought. And this is one of the more charitable cases — the pattern repeats without even that qualification, conclusions stated as definitive with no acknowledgment of incomplete coverage.
This is qualitatively different from a failed search. A failed search is a signal to the investigator to try harder. A confident false negative is a signal to move on — and miss the evidence. Farquhar et al. (2024) call this confabulation; Kalai et al. (2025) attribute it to training incentives that reward committing to a plausible conclusion over expressing incompleteness. No API change eliminates this risk. The failure occurs at the conclusion step, not the retrieval step.

Incorrect conclusion with partial uncertainty acknowledged
2. Over-eager delegation and goal persistence
Task 19 illustrates what Boddy and Joseph (2025) term goal persistence in the agentic AI safety literature: an agent continuing to pursue a failing approach beyond the point where it’s reasonable to do so. The model committed to a delegation-heavy investigation path (EventWhisper → crash reports → WER analysis) and never fell back to the simpler search_files_by_name call that solved the task in Mode 2 in 17 seconds.
Wang et al. (2025) find that agents consistently fail to switch strategies even when a simpler path is available. Stechly, Valmeekam, and Kambhampati (2024) show why: LLMs cannot reliably self-verify that a current approach has failed.
There’s currently no cost threshold or explicit failure trigger in the architecture. A wrong delegation path can negate the delegation benefit entirely. This is the clearest area where the architecture needs hardening.
Task 17 (shared VM folders) showed a related but distinct failure: the model repeatedly called get_registry_key against hives that weren’t loaded, because it lacked a guard condition checking whether a hive was available before attempting to query it. That one is a correctable implementation gap rather than a structural problem.
3. Anchoring bias — in both human and AI investigators
Task 18 (malware identification) returned the same incorrect answer across all three modes, including manual investigation. Every mode anchored on piccies.exe, the first strongly-evidenced malware candidate, without adequately considering alternatives. The AI didn’t introduce a new failure mode here. It replicated an existing human cognitive bias.
Task 16 (GPS photo identification) showed the same pattern. Prior session context primed both MCP modes to return to the first geolocated image rather than searching for additional candidates. The context retention framing explains why it happened; the anchoring framing explains why the model didn’t correct itself once it had the first candidate in hand.
Huang et al. (2026) show this mirrors human first-candidate lock-in. If you’re deploying AI assistance expecting it to be immune to biases present in its training data, that expectation is worth revising.
4. Session fragility and context window limits
Both MCP modes depend on an uninterrupted session to accumulate context, and that dependency has a real reliability cost. Session termination occurred twice during the full case, discarding all accumulated context. Task 14’s email evidence chain had to be fully re-established from scratch as a result, adding significant time to a task that should have been trivial given what had already been retrieved earlier in the session. Any operational deployment needs to account for this explicitly, as context is not persisted anywhere and requires manual intervention.
Mitigating this is worth exploring: periodic context summarization, saving intermediate findings to a persistent store, or even a dedicated playbook that formats and snapshots the current investigative context for resumption in a new session. Most of these would benefit from some awareness of context window size to trigger proactively rather than after the fact.
The Forensic Soundness Question
Throughout this project, there was a recurring tension between forensic soundness and useful investigative assistance.
Forensic evidence has strict requirements. ISO/IEC 27037:2012 defines three core principles:
- Auditability: actions must be independently verifiable
- Justifiability: actions must be explainable
- Repeatability: same procedures yield the same conclusions
The ACPO Good Practice Guide requires that a record of all actions applied to digital evidence be created and preserved so that an independent third party can examine those processes and reach the same conclusions.
AutopsyMCP addresses these through:
- Read-only access: no tool can modify the forensic image (ACPO Principle 1)
- Structured audit logging: every tool invocation recorded with timestamp, arguments, response summary, session ID, written independently of the MCP client (ACPO Principle 2)
- Repeatability: the audit log records what happened in a session, but cannot guarantee a second run follows the same path (ACPO Principle 3, partially addressed)
Because the model’s tool selection is non-deterministic, the same query may produce different tool sequences, and different conclusions, across independent runs. Individual tool outputs are reproducible; the reasoning path that selected and sequenced them is not.
Nicholson (2026) demonstrates empirically that even at temperature zero, LLMs can produce distinct outputs across repeated invocations of the same prompt.
The deeper issue is that these frameworks were designed around deterministic, human-executed procedures. An LLM reasoning layer doesn’t fit that model.
Audit logging is necessary but not sufficient. Sufficiency would require either deterministic tool selection, which would forfeit the analytical flexibility that makes the system useful, or a formal framework for quantifying reasoning variability — neither of which currently exists. The open question for the field is what forensic soundness should mean when the analytical process is non-deterministic.
Practical Takeaways
If you’re a forensic practitioner or incident responder:
The 63% effort reduction held consistently across both evaluation sets. The knowledge-equalizer effect is real: registry timestamp parsing, Chrome transition bitmask decoding, SQLite schema interpretation, all handled transparently from a natural language query. For triage, initial case orientation, and structured data retrieval, MCP-assisted investigation performs comparably to manual while requiring dramatically less effort and fewer context switches.
The accuracy cost is there too (16/20 vs 19/20). The failure modes cluster predictably: confident false negatives at the conclusion step, anchoring on first-found evidence, over-delegation on tasks where a simpler approach exists. Knowing where the failures concentrate lets you design your workflow around them. Use AI assistance for retrieval and correlation; apply explicit human judgment at the conclusion step; treat confidently-stated negative findings with particular skepticism.
If you’re thinking about AI tooling for security workflows more broadly:
The MCP architectural pattern is a meaningful design choice. Constraining an LLM to operate only through logged, verifiable tool calls changes how reliable and auditable the system is. It can no longer reason freely from training knowledge; it has to retrieve and correlate evidence. The failures that remain after applying this constraint are failures of reasoning, not failures of access. That’s a narrower problem to address.
On forensic soundness specifically:
AI in DFIR is happening regardless of whether frameworks have caught up. The more productive question is where existing standards hold and where they need extending. Current standards assume deterministic human procedures; we can see where LLM-assisted workflows diverge, and closing that gap is feasible.
Future Work
- Fallback mechanisms for delegation: cost thresholds or explicit failure triggers to prevent goal persistence on wrong paths
- Session continuity: context is lost on termination and cannot be recovered; mitigations like a snapshot playbook or periodic summarization are worth exploring
- Aggregate API endpoints: Autopsy’s GUI surfaces a range of views that the current API doesn’t yet expose
- Cryptographic audit log integrity: the current log is functional but not tamper-evident, which is a standard expectation for forensic audit trails
- Multi-evaluator studies: testing the knowledge-equalizer effect with investigators at varying skill levels. The hypothesis that less experienced practitioners benefit most requires proper evidence with practitioners, not just a single-evaluator study
The concurrent independent release of the official Autopsy 4.23.0 MCP integration by the Autopsy development team in April 2026 validates the research direction. The open questions are now about the conditions under which AI-assisted workflows are reliably usable in practice. I hope this work contributes to answering them.
Appendix: Full Evaluation Results
Micro-benchmark: Task Definitions & Full Results
| # | Source Image | Category | Task Question | Expected Answer | Mode 1 Time | Mode 1 Answer | Mode 1 Result | Mode 1 Steps | Mode 2 Time | Mode 2 Answer | Mode 2 Result | Mode 2 Queries | Mode 3 Time | Mode 3 Answer | Mode 3 Result | Mode 3 Queries |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | GregSchardt | Registry | What was the last recorded computer shutdown date/time? | August 27, 2004, at 15:46:33 UTC | 6:55 | 2004-08-27 15:46:33.1092164 Z | Correct | 4 | 2:21 | 2004-08-27 at 16:46:27 BST (Event ID 6006 – EventLog service stopped, Record #141) | Correct | 1 | 1:04 | Friday, 27 August 2004 at 15:46:33 UTC | Correct | 1 |
| 2 | GregSchardt | Registry | What are the IP address and MAC addresses of the computer? | 192.168.1.111, 00:10:a4:93:3e:09 | 2:25 | 192.168.1.111, 10a4933e09 | Correct | 3 | 0:38 | Hostname: N-1A9ODN6ZXK4LQ | MAC: 00:10:A4:93:3E:09 | LAN IP: 192.168.1.111 | APIPA: 169.254.242.213 | Correct | 1 | 1:53 | 192.168.1.111 (subnet 255.255.255.0, gateway 192.168.1.1) | Partial | 1 |
| 3 | GregSchardt | Registry | List the network cards used by this computer | (1) Compaq WL110 Wireless LAN PC Card (2) Xircom CardBus Ethernet 100 + Modem 56 | 0:55 | Xircom CardBus Ethernet 100 + Modem 56, Compaq WL110 Wireless LAN PC Card | Correct | 2 | 8:56 | Xircom CardBus Ethernet, Agere Orinoco PC Card | Partial | 1 | 1:11 | Xircom CardBus Ethernet 100 + Modem 56 — Ethernet Interface, Xircom CardBus Ethernet 100 + Modem 56 — Modem Interface | Partial | 1 |
| 4 | GregSchardt | Browser | What websites was the suspect (Mr. Evil) accessing? | mobile.msn.com (MSN Hotmail email service) | 0:45 | mobile.msn.com (and others) | Correct | 4 | 0:34 | mobile.msn.com (and others) | Correct | 1 | 0:33 | mobile.msn.com (and others) | Correct | 1 |
| 5 | Stanley | File Discovery | Are there any files >50MB in the image? If so, what are their names? | GCR 2015 version.doc, GCR.doc | 0:59 | GCR 2015 version.doc, GCR.doc | Correct | 3 | 1:55 | $Bad/$Bad-slack: ~378 MB each (NTFS metadata) | IMG_20171119_194709.jpg: 3.4 MB | sendmail.exe: 911 KB | Not Found | 1 | 0:56 | $BadClus:$Bad 378.3 MB, $BadClus:$Bad-slack 378.3 MB, curly_1709_librivox.zip 149.5 MB, JRE.cab 96.4 MB, GCR 2015 version.doc 92.4 MB, GCR.doc 92.4 MB | Correct | 1 |
| 6 | Stanley | System | What is the sector length of vol3 in the Stanley.E01 image? | 614400 | 0:08 | 614400 | Correct | 3 | 0:10 | 3,504 sectors and 1,794,048 bytes | Incorrect | 1 | 0:17 | 614400 | Correct | 1 |
| 7 | Norman | Metadata | Can you determine the make and model of camera used for the rose picture? | NIKON CORPORATION, NIKON D40 | 0:11 | NIKON CORPORATION, NIKON D40 | Correct | 3 | 0:16 | NIKON CORPORATION, NIKON D40 | Correct | 1 | 0:21 | NIKON CORPORATION, NIKON D40 | Correct | 1 |
| 8 | Norman | User Activity | In which two years has the bulk of activity taken place in the DFI? | 2014 and 2017 | 0:37 | 2014 and 2017 | Correct | 3 | 1:25 | 2014 and 2017 | Correct | 1 | 1:12 | 2015 and 2017 | Partial | 1 |
| 9 | IPTheft | File Discovery | Are there files containing confidential corporate data? Any evidence of obfuscation? | Yes | 2:07 | Yes | Correct | 5 | 2:57 | Yes | Correct | 1 | 0:03 | Yes | Correct | 1 |
| 10 | Animal | Communication | Is there evidence of James Jones communicating with third parties? | Yes | 0:33 | Yes | Correct | 3 | 0:34 | Yes | Correct | 1 | 0:41 | Yes | Correct | 1 |
Full Case Investigation: Task Definitions & Full Results (Beethomahler)
| # | Category | Task Question | Expected Answer | Mode 1 Time | Mode 1 Answer | Mode 1 Result | Mode 1 Steps | Mode 2 Time | Mode 2 Answer | Mode 2 Result | Mode 2 Queries | Mode 3 Time | Mode 3 Answer | Mode 3 Result | Mode 3 Queries |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Verification | What are the last 4 digits of the verified SHA1 hash? | 8326 | 0:11 | 8326 | Correct | 3 | 2:11 | N/A | Not Found | 1 | 1:28 | N/A | Not Found | 1 |
| 2 | Device | Were any external devices attached? If so, provide the device ID. | 5&18f54cb7&0&1 | 0:14 | 5&18f54cb7&0&1 | Correct | 3 | 0:16 | 5&18f54cb7&0&1 | Correct | 1 | 0:16 | 5&18f54cb7&0&1 | Correct | 1 |
| 3 | Browser | Did the suspect bookmark any non-contraband related web pages? | No | 0:12 | No | Correct | 2 | 0:10 | No | Correct | 1 | 0:10 | No | Correct | 1 |
| 4 | Registry | On what date was the OS installed? (YYYY-MM-DD) | 2023-02-11 | 0:10 | 2023-02-11 | Correct | 2 | 0:11 | 2023-02-11 | Correct | 1 | 0:14 | 2023-02-11 | Correct | 1 |
| 5 | Registry | OS install date in original UNIX time format? | 1676092305 | 0:41 | 1676092305 | Correct | 3 | 0:05 | 1676092305 | Correct | 1 | 0:18 | 1676092305 | Correct | 1 |
| 6 | Registry | What are the last 5 digits of the OS Product ID? | 85033 | 0:02 | 85033 | Correct | 1 | 0:05 | 85033 | Correct | 1 | 0:05 | 85033 | Correct | 1 |
| 7 | System | What are the first 8 digits of the device ID? | 6ce70ff9 | 0:16 | 6ce70ff9 | Correct | 1 | 0:09 | 6ce70ff9 | Correct | 1 | 0:05 | 6ce70ff9 | Correct | 1 |
| 8 | System | What is the timezone of the seized computer? | Europe/London | 0:02 | Europe/London | Correct | 1 | 0:06 | Europe/London | Correct | 1 | 0:06 | Europe/London | Correct | 1 |
| 9 | Anti-forensics | When did the suspect research keeping files private/hidden? (YYYY-MM-DD HH:MM:SS GMT) | 2023-02-17 15:20:58 GMT | 0:23 | 2023-02-17 15:20:58 GMT | Correct | 1 | 1:19 | 2023-02-17 15:20:58 GMT | Correct | 1 | 1:20 | 2023-02-17 15:20:58 GMT | Correct | 1 |
| 10 | File Transfer | Which file transfer service was used to deliver files to the suspect? | WeTransfer | 0:16 | WeTransfer | Correct | 3 | 0:14 | WeTransfer | Correct | 1 | 0:18 | WeTransfer | Correct | 1 |
| 11 | File Transfer | What are the first 8 characters of the received container’s filename? | 71cc3213 | 0:37 | 71cc3213 | Correct | 5 | 0:07 | 71cc3213 | Correct | 1 | 0:07 | 71cc3213 | Correct | 1 |
| 12 | File Transfer | When was the container saved to disk? (YYYY-MM-DD HH:MM:SS GMT) | 2023-02-23 10:45:36 GMT | 0:46 | 2023-02-23 10:45:36 GMT | Correct | 3 | 0:10 | 2023-02-23 10:45:36 GMT | Correct | 1 | 0:16 | 2023-02-23 10:45:36 GMT | Correct | 1 |
| 13 | Communication | Who sent the file to the suspect? | DinnyDjanko | 0:01 | DinnyDjanko | Correct | 1 | 0:08 | DinnyDjanko | Correct | 1 | 0:13 | DinnyDjanko | Correct | 1 |
| 14 | Communication | What was the suspect’s WeTransfer MFA code? | 622191 | 0:23 | 622191 | Correct | 2 | 0:53 | 622191 | Correct | 1 | 3:03 | 622191, 335306, 335014 | Correct | 1 |
| 15 | File Analysis | What is the full name of the largest file in the WeTransfer container? | McFarlane-BTAS-Batman-Catwoman-Version-2-header.jpg | 0:41 | McFarlane-BTAS-Batman-Catwoman-Version-2-header.jpg | Correct | 4 | 0:53 | McFarlane-BTAS-Batman-Catwoman-Version-2-header.jpg | Correct | 1 | 1:18 | McFarlane-BTAS-Batman-Catwoman-Version-2-header.jpg | Correct | 1 |
| 16 | Metadata | A photo contains GPS coordinates — identify the street address. | Burton Road | 1:27 | Moon Flower Ct or Burton Road | Correct | 4 | 2:32 | Brown Trail | Incorrect | 1 | 1:47 | 39.9025722, -97.2622833 | Incorrect | 1 |
| 17 | User Activity | What did the suspect share to their VM? Folder names? | Downloads, Malware | 0:45 | Malware, Downloads | Correct | 2 | 2:34 | Malware, Downloads | Correct | 1 | 2:12 | Malware, Downloads | Correct | 1 |
| 18 | Malware | Who was malware sent to, what was it, and when? (who_what_when) | dinnydjanko@gmail.com, Solimba, 2023-03-06 06:57:26 | 2:51 | dinnydjanko@gmail.com_piccies.exe_2023-02-28_13:03:48 | Incorrect | 4 | 3:40 | dinnydjanko@gmail.com_piccies.exe_2023-02-28_13:03:48 | Incorrect | 1 | 1:39 | dinnydjanko@gmail.com_Multi:Agent-ES_2023-02-28_13:03:48 | Incorrect | 1 |
| 19 | Application | WMP installation error code and time? (errorcode_HH:MM:SS) | 0x80070005, 21:12:15 | 2:41 | 0x80070005, 21:12:15 | Correct | 3 | 0:18 | 0x80070005, 21:12:15 | Correct | 1 | 4:45 | c000001d_12:20:55 | Incorrect | 1 |
| 20 | Browser | How many times was wetransfer.com opened (excl. refreshes)? Latest timestamp? | 3, 2023-03-06 06:03:11 | 8:38 | 3, 2023-03-06 06:03:11 | Correct | 6 | 3:09 | N/A | Not Found | 1 | 1:46 | 4, 2023-03-06 06:03:11 | Partial | 1 |
The full dissertation may be available on request once my results are finalized. Code is available on GitHub. Feel free to reach out if you have related work, questions, or feedback.